
How Much Should We Trust Publication Bias Detection Techniques?
Publication bias occurs when the distribution of observed effects differs from the distribution of all such effects. Usually, this means there is some filter based on the magnitude or direction of the effect (positive or negative). Crucially, we do not observe all effects, so we must infer whether publication bias has occurred.
Publication bias has been studied since at least 1959. More recently, a number of techniques in meta-analysis have been used to try and estimate both whether publication bias has occurred and what the average effect would have been without publication bias. These techniques need a number of assumptions to be true to work.
A new working paper from Rafael Román-Caballero and Miguel A. Vadillo, “A meta-analyst should make informed decisions: Issues with Bayesian model-averaging meta-analyses”, argues that these methods can be very unreliable and overestimate the extent of publication bias that exists. I argue that yes, when used incorrectly, the publication bias detection methods will not work, but the methods in the paper to show this are unconvincing and the conclusions go too far.
Summary
The paper’s main argument is that publication bias detection methods can flag up publication bias when none exists, and they can say no effect exists when it actually does.
Their argument rests on two strategies. The first is pure simulations where no publication bias exists. They simulate original studies, then simulate replications of these original studies, but the replications use the original estimates as guides for sample size in their power calculations. They find in their simulations that the publication bias techniques indicate publication bias, and their corrected average estimates are biased toward zero.
The second is where they collect several databases of pre-registered replications that are not contaminated by publication bias. They use the publication bias methods on these and again find that the techniques indicate publication bias.
So, two different strategies, and both show publication bias detection methods can be unreliable, right? Well, I agree they can be unreliable, but I don’t agree either of the strategies in this paper shows that.
Problems
First, the simulations. Keep in mind that generally how publication bias methods work is they look for a correlation between the standard error and the effect size. In all simulations, they use Cohen’s $d$ as their standardized metric. In Cohen’s $d$, the formula to estimate the standard error includes the effect size, Cohen’s $d$, itself. In the initial simulations, it is no surprise to see the standard error and the effect size correlated, as they are in figure 3, because it happens by construction. That is not the main problem though. The simulated replications in figure 3 base their sample size on the size of the original simulated effects. All replications have the same power. Replications of bigger effects need less sample size to achieve the same power. Sample size is directly related to the size of the errors. Therefore, a correlation is introduced through the simulated replication process.
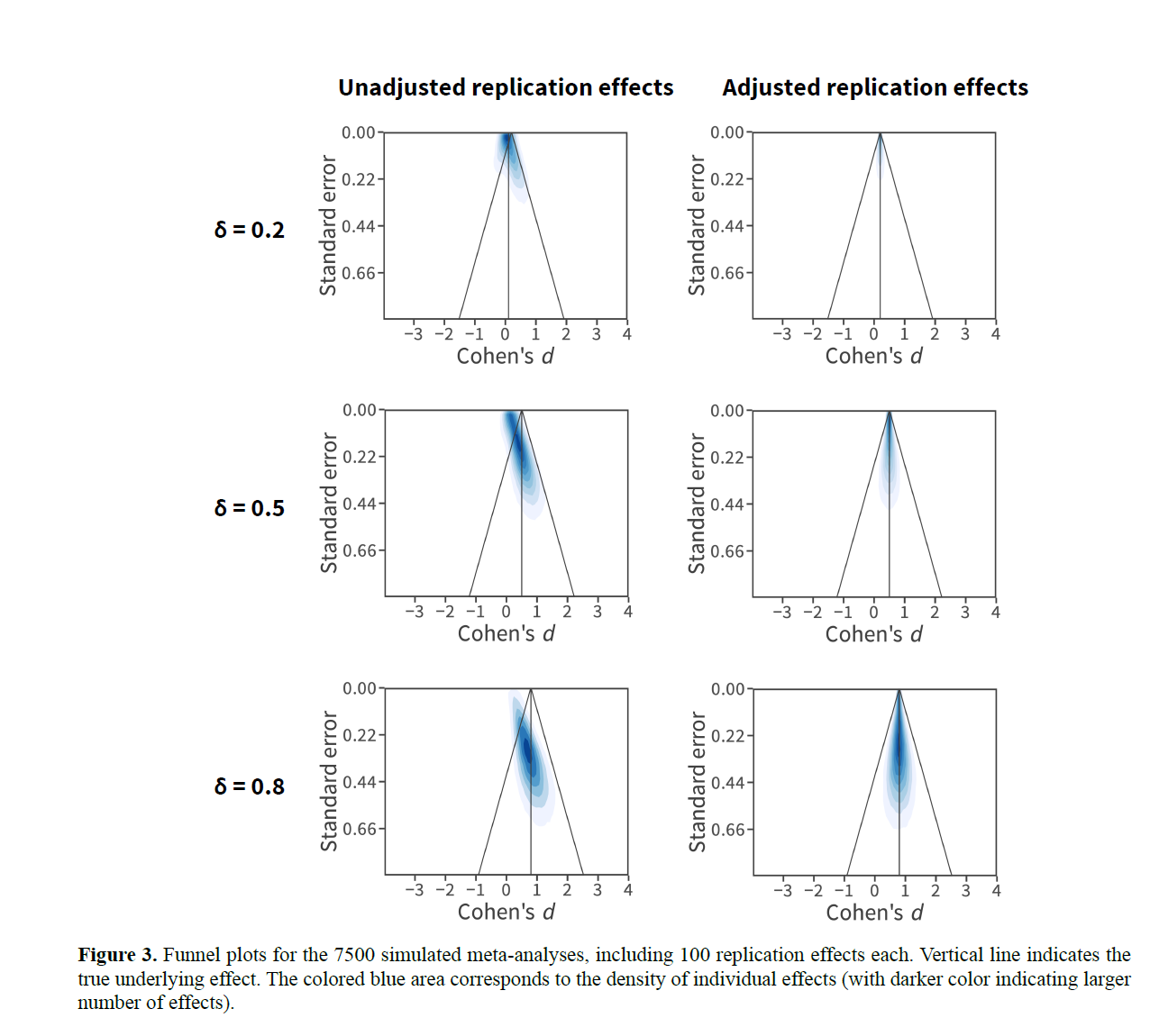
As for the empirical part, it’s a similar story with an additional element. They take a bunch of replications and combine them, then test for publication bias and estimate the effect after this non-existent bias is removed. The authors are aware of a possible limitation with this. In their own words:
“…[E]ach of these data sets comprises studies on disparate processes, using radically different procedures and designs. Few meta-analysts would be interested in pooling such diverse effects.”
In other words, they are combining studies that are looking at completely different things! For me, this is fatal for the empirical part of the paper. This is “combining incommensurable results” and I cannot see any good reason for doing so. For example, they are combining a replication of how much people agree “the earth is flat” with a replication of the effect of less caveolin-1 in mice!
This is their defense:
“Yet, the heterogeneity that we found within each of those data sets ($I^2$ = 88.4%) was only slightly higher than the average heterogeneity observed in psychological meta-analyses, often hovering around 70%. Furthermore, asymmetry-based methods and RoBMA overdetected bias not only in the datasets with larger heterogeneity but also in the most homogeneous dataset…”
The argument here is that the average psychology meta-analysis contains as little information as an estimate that combines mice cell behavior and human beliefs about objectivity. I hope this is not true. For starters, $I^2$ is an estimate of the percent of heterogeneity that is not due to sampling error. It is not an absolute measure of heterogeneity. Even if it was, it wouldn’t matter. The studies that are combined are incommensurable.
However, if they are so incommensurable, how come the publication bias methods suggest there is publication bias in this collection of studies every time? What would we expect? Well, once again, these are replications. The sample size of the replications is based on the size of the effect in the original studies, through power calculations. As we know, the size of the standard error is related to the sample size. So the standard error and the effect size will be correlated. Therefore, these methods pick up this correlation and point to publication bias where none exists.
The authors and others have argued that this shows if effects are heterogeneous, and researchers have a good idea of the effect size ex-ante, and therefore efficiently select sample sizes to all have, for example, 80% power, there will be a correlation between the errors and the effects. This is true but would mean all the studies are estimating effects that are not only known to be different but we know how they are different. We can rank the effects. Should they be doing that? No! In general, in a (random effects) meta-analysis, we assume each study is estimating a different effect and estimate the average of the effects, but the differences are assumed to be random, drawn from a common underlying distribution.
When this is not the case, they are not i.i.d, nor exchangeable1. What that means is any inference we do from this model will be off. This is important because when we test for publication bias, we are not just describing the data, we are doing inference. We are trying to say something about the underlying population, not just the sample we have. It’s important to think about why you are doing meta-analysis in the first place. More than likely, you want to say something about the underlying distribution of all such effects. For example, what’s the mean and variance of that distribution? You can then use that to predict what a new effect, a new draw from the underlying distribution, would be. How good would this treatment be if we did it again? This is predictive inference. With the models we use in meta-analysis, this is only really possible if you can meet at least the assumption of exchangeability. The same goes for any inference about the extent of publication bias.
However, given we know why the replications differ, it is trivially easy to make them conditionally exchangeable, and our inference will be much better. We just condition on what accounts for the systematic difference in effect sizes. In fact, the authors do this:
“An alternative to disabling asymmetry-based methods is to ensure that the meta-analytic model explicitly contemplates any potential moderator that could potentially give rise to small-study effects for reasons unrelated to bias. In our analysis and simulations, it was trivially easy to account for funnel-plot asymmetry by simply entering the original effects (or the latent true effect, in the case of the simulations) as a predictor in the model. Logically, this strategy cannot be followed in most meta-analyses.”
They included the effect size each replication was trying to replicate in a meta-regression, and this removed the correlation between the effect size and the errors (see right-hand side of figure 3 above). So, if you believe that you have a set of efficiently powered studies, you can simply incorporate that information into your model. How? Well, you could split your sample into groups of effect sizes you believe are similar, or you could simply do a meta-regression with an appropriate moderator, like sample size. If you do not model this information, then your inference will likely be off.
This applies whenever you have observable drivers of heterogeneity in effect sizes. Think about what you are trying to do when you group effects in a meta-analysis. If you know why effects will be systematically different, you need to model this if you want to do inference.
-
See Gelman et al. (2013) or Meager (2022) for a discussion of the importance of exchangeability in hierarchical models. ↩