True P Values
layout: single title: “Taleb Paper on P-Hacking” date: 2024-12-12 use_math: true published: false categories: blog tags: Publication Bias Meta-Analys...
layout: single title: “Taleb Paper on P-Hacking” date: 2024-12-12 use_math: true published: false categories: blog tags:
I’m sure Taleb has forgotten more about probablity than I will ever know, but I find I don’t agree with the conclusions of his paper on p-hacking.
The paper argues that the commonly used thresholds for significance, called $\alpha$, are too high and therefore over-reject the null. That they over-reject because of the extreme skewness of the p-value distribution. What this means is that there are too many false-positives, or type I errors, in the scientific literature.
He derives a distribution function for p-values1 that only depends on the median p-value and the sample size. He introduces what he calls “true” p-values which he defines as the expected value over multiple different samples (the true p-value $( p_s )$ converges in probability: $\frac{1}{m} \sum_{i=1}^m p_i \xrightarrow{P} p_s$). He shows that you could have this “true” or average p-value be greater than 0.05 and yet most individual p-values would be lower than 0.05. He calls this 0.05 “true” p-value borderline, as in on the border between significant and non-significant. Yet, he says, if teh “true” p-value is bordeline, and the vast majority of indvidual tests will reject the null then the test is not calibrated correctly. There are too many “false” rejections of the null. It is easy for reasearchers to p-hack by testing multiple subsamples until they get a statistically signifcant result.
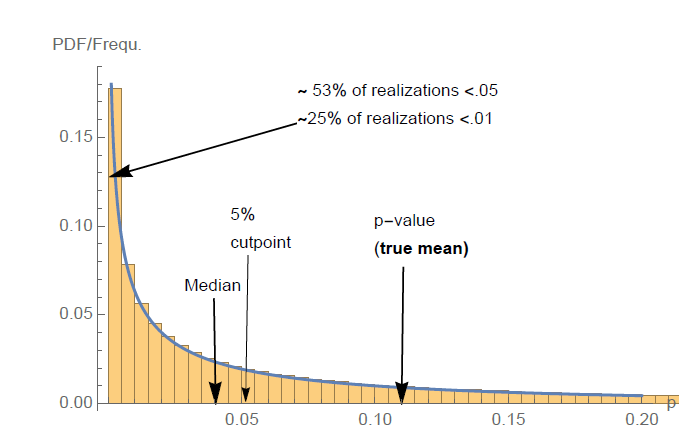
What is my issue with this example? In short, if the average p-value is 0.05 then the null model is false and most tests correctly reject it. When the null model is correct, with all the assumptions that entails, then the p-value distribution will be uniform (or stochastically greater than uniform)2. So basically they have a uniform distrubtion or are left skewed, like this:
Given the values a p-value can take are from 0-1, a uniform distribution of p-values will have a mean and median of 0.5. So when the null hypothesis is correct, the mean and the median p-values, these “true” p-values as he calls them, cannot be less than 0.5 (when it’s stochastically greater than uniform the mean and median will be greater). Back to Taleb’s example, the mean p-value is 0.05, obviously less than 0.5. Therefore, the null is false and it is correct to reject it.
I am at pains to point out that even if teh null hypothesis is rightfully rejected, that does not mean that, for example, there is an efefct of some treatment rather that no effect. The null hypothesis is a test of a model. The null hypothesis model is not just that a certain parameter is zero.
I think there are two things great about Taleb’s paper:
It is a piecewise pdf with the split at 0.5 median p-value. ↩
See Cassella and Berger pages 397-398. ↩
layout: single title: “Taleb Paper on P-Hacking” date: 2024-12-12 use_math: true published: false categories: blog tags: Publication Bias Meta-Analys...
Publication bias occurs when the distribution of observed effects differs from the distribution of all such effects. Usually, this means there is some filter...
Cohen’s $d$ is commonly used as the standardized effect size in meta-analysis. Meta-analyses now also tend to include tests of publication bias. Both of thes...
I was reading O’Rourke’s history of meta-analysis paper and he mentions what is possibly the first paper to systematically look at publication bias based on ...